Natural language prompts. Computer vision. A robot arm that watches, understands, and acts.
This is what happens when multimodal AI stops being a research demo and becomes something you can build.
What This Actually Is
A robot arm with a camera. You tell it what to do in plain English. It uses vision to identify objects, understands your intent from the language, and executes the task.
"Pick up the red block."
"Move the cup to the left."
"Stack these items."
The system processes the camera feed, identifies objects and their positions, interprets the command, plans the motion, and executes. All in real-time conversation with the user.
This isn't new conceptually. Vision-language-action models have existed for years. What's new is that someone built this as a project, not a multi-year research initiative.
The Questions People Ask
"Can you do this with the free version of Gemini or is paid required?"
That's the first question in the comments. Not about the technical architecture. Not about the vision pipeline. About whether you can build this without spending money.
That question reveals where we are. The barrier to building multimodal robotics isn't knowledge or capability. It's API access.
"Could you use V-JEPA-2AC instead?"
Alternative model suggestions in the comments. The assumption is that you're composing components, not building from scratch. The question is which pre-trained models to combine, not whether to train your own.
The Infrastructure That Makes This Possible
This works because the hard parts are solved:
- Vision models that identify and track objects reliably
- Language models that parse natural instructions
- Robotics APIs that handle motion planning
- Integration frameworks that connect them
The builder assembles components. The innovation is in the integration, not the individual pieces.
Five years ago, each of these components required specialist expertise. Now they're APIs you call. The robotics equivalent of what happened to web development when cloud infrastructure matured.
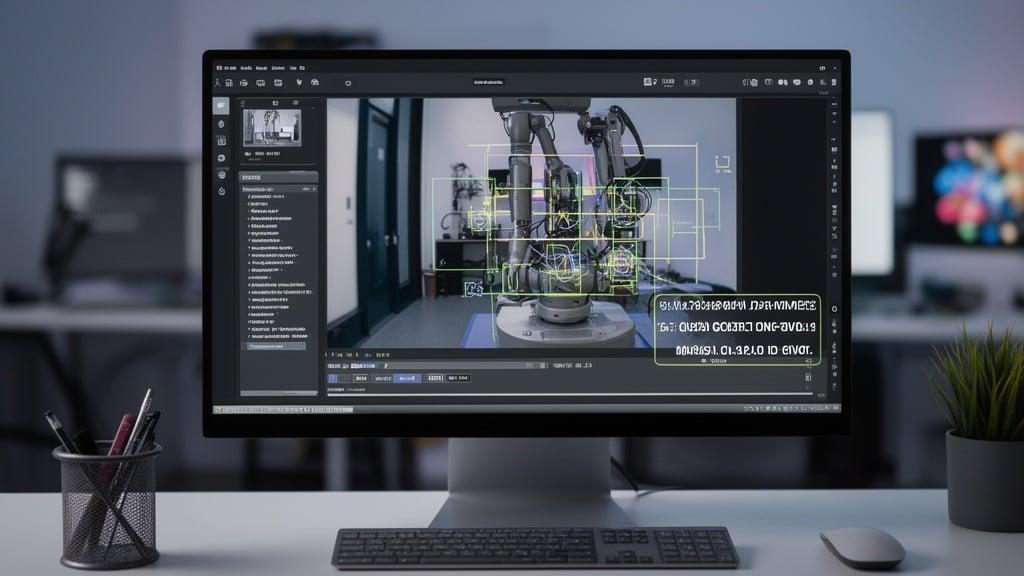
What the Video Shows
The camera feed is visible. The AI narrates what it's doing as it works through the prompt. This transparency is interesting—you see the system's interpretation of the task, not just the execution.
The narration isn't just status updates. It's the system explaining its reasoning. Why it's reaching for this object. What it plans to do next. Essentially making the decision process observable.
This matters for trust and debugging. When the robot does something unexpected, you can review the narration to understand why. The system's logic is exposed, not hidden in a black box.
The Gap Between Demo and Deployment
The demo looks clean. The environment is controlled. Objects are distinct and well-positioned. Lighting is good. The camera has a clear view.
Real environments aren't like this. Clutter, occlusion, poor lighting, objects that look similar, ambiguous language, tasks that require multi-step reasoning with intermediate failures.
Every robotics demo faces this gap. The question isn't whether the demo works. It's how far the capability degrades when conditions get messier.
Does it handle partial occlusion? Can it recover from failed grasps? What happens when you give ambiguous instructions? These determine whether this stays a demo or becomes a deployed system.
The Multimodal Integration Question
This combines three modalities: vision (what's in the scene), language (what the user wants), and action (how to move the robot). Each modality has its own models and representations.
The challenge is integration. Vision models output object detections. Language models output intent representations. Motion planners expect position targets and trajectories. Something has to translate between these representations.
That "something" is where the real work happens. It's not glamorous. It's not publishable as a breakthrough. But it's what determines whether the system works reliably.
How do you map detected objects to actionable positions? How do you handle ambiguity when language is vague? How do you replan when vision updates during execution?
These integration challenges don't have clean solutions. They require engineering judgment and iteration.
Cost and Accessibility
The question about free vs. paid APIs is more significant than it seems. It determines who can build these systems.
If this requires paid API access with per-request costs, it's not accessible for experimentation. Students can't iterate freely. Hobbyists can't explore. Only teams with budgets can develop applications.
If it works with free tiers, suddenly thousands of people can experiment. The innovation space expands dramatically.
This pattern has played out repeatedly: cost barriers determine innovation velocity more than technical barriers. When AWS reduced compute costs, cloud applications exploded. When transformer APIs became accessible, LLM applications exploded.
Robotics is hitting the same inflection point. The question is how fast costs drop and access expands.
What This Enables (Maybe)
The obvious applications: warehouse automation, manufacturing assistance, household robots that follow instructions.
But those applications have been "five years away" for decades. The limiting factor has never been the technology in demos. It's reliability in uncontrolled environments, cost of deployment, complexity of integration with existing workflows.
Does this change those constraints? Unclear.
Making the integration easier is valuable. Reducing the expertise required to build robot systems matters. But easier demos don't automatically translate to deployable products.
The real test: are companies deploying systems like this in production? Not demos. Not pilots. Actual scaled deployments where reliability and cost matter.
That data isn't visible yet.
The Boring Infrastructure Problem
Notice what's not in the demo: error recovery, continuous learning, fleet management, monitoring, safety protocols, failure logging.
Those aren't exciting. They don't make good videos. But they're 80% of the work for deployed systems.
A robot that follows prompts in controlled conditions is impressive. A robot that follows prompts reliably across varied conditions, recovers from failures, improves with usage, and operates safely around humans—that's a product.
The gap between these is vast.
Where This Goes
If multimodal models continue improving and costs continue dropping, this pattern becomes standard. Natural language interfaces for robotic systems. Vision-language-action integration as a solved component.
The question then becomes: what applications become viable that weren't before? Where does lower cost and easier integration unlock real deployment?
Or does this remain perpetually in the "impressive demo" category, where technical capability exists but practical constraints prevent widespread adoption?
Robotics has lived in that space for a long time. Demos that work brilliantly. Products that struggle. The gap between capability and deployment is stubbornly wide.
Maybe multimodal AI narrows it. Maybe it doesn't. The demos get better every year. The deployed systems improve much slower.
That's the pattern to watch.